cmaes
Lightweight Covariance Matrix Adaptation Evolution Strategy (CMA-ES) implementation for Python 3.
Description
cmaes
![]()

:whale: Paper is now available on arXiv!
Simple and Practical Python library for CMA-ES. Please refer to the paper [Nomura and Shibata 2024] for detailed information, including the design philosophy and advanced examples.
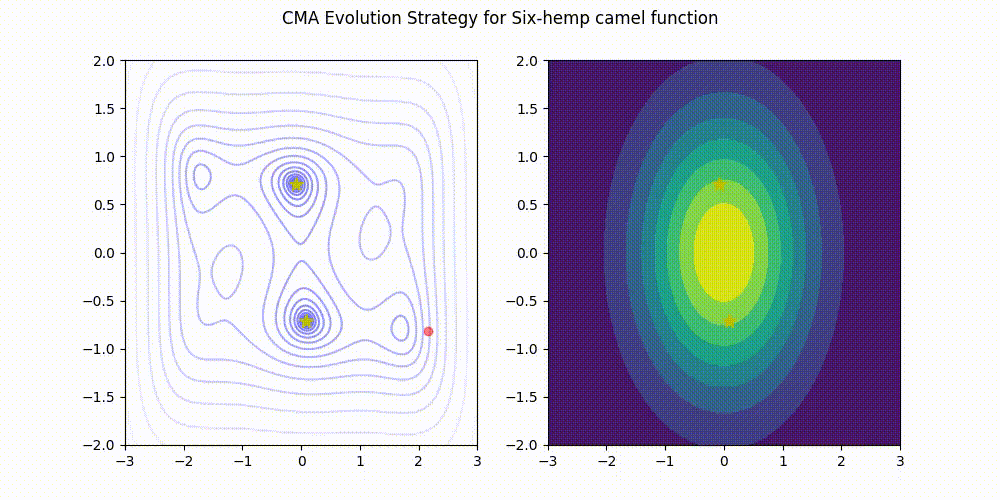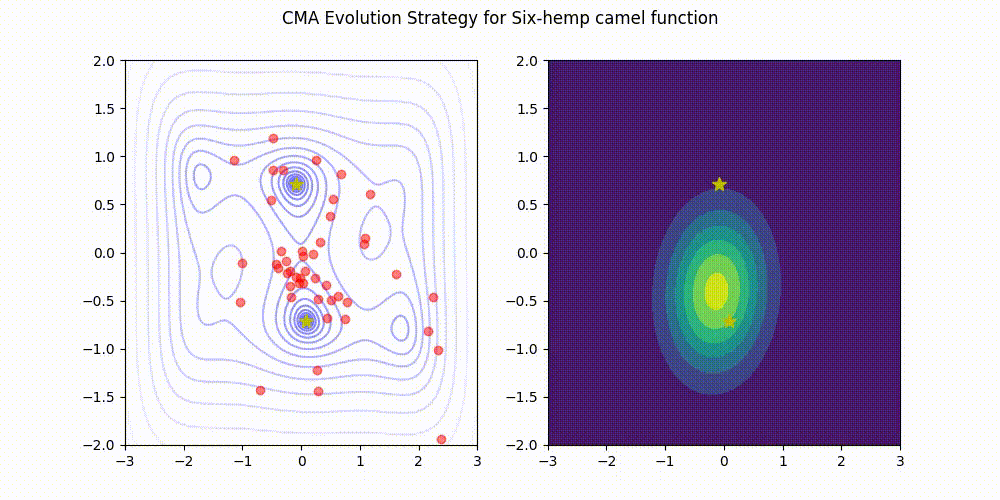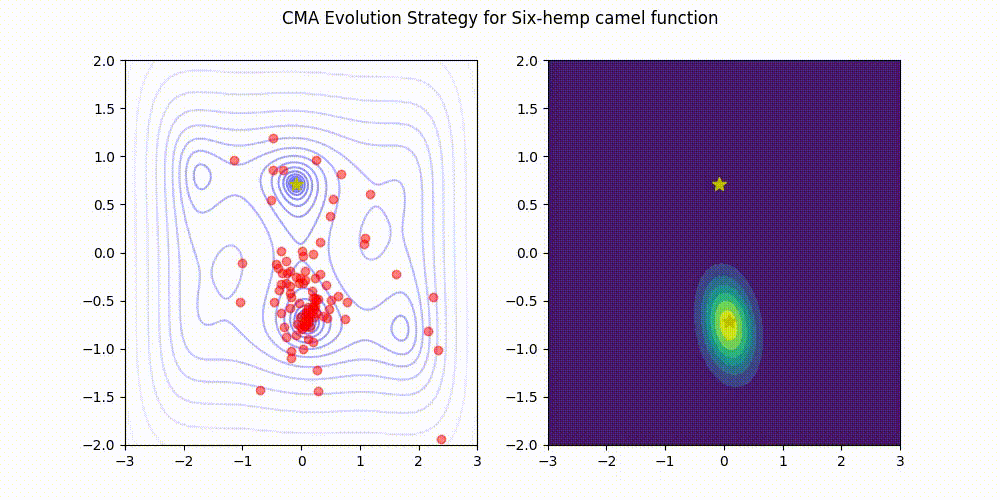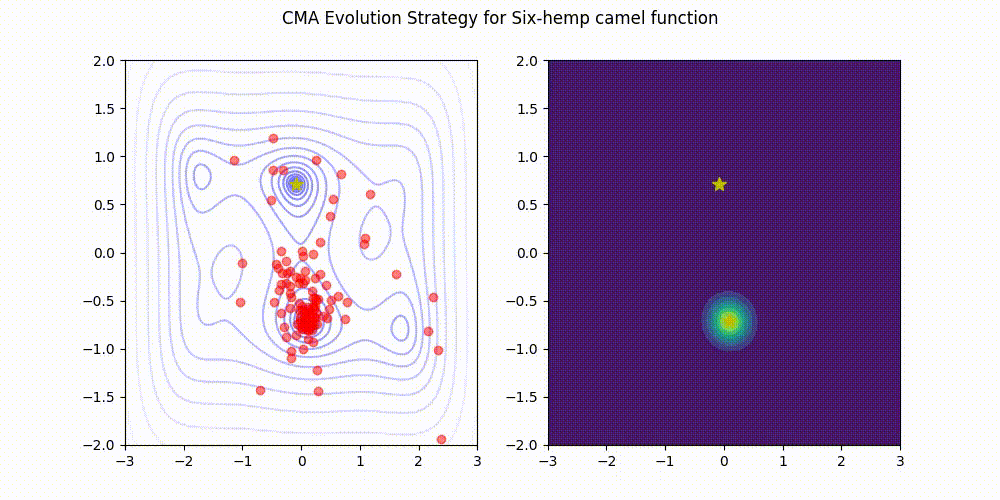
Installation
Supported Python versions are 3.8 or later.
$ pip install cmaes
Or you can install via conda-forge.
$ conda install -c conda-forge cmaes
Usage
This library provides an "ask-and-tell" style interface. We employ the standard version of CMA-ES [Hansen 2016].
import numpy as np
from cmaes import CMA
def quadratic(x1, x2):
return (x1 - 3) ** 2 + (10 * (x2 + 2)) ** 2
if __name__ == "__main__":
optimizer = CMA(mean=np.zeros(2), sigma=1.3)
for generation in range(50):
solutions = []
for _ in range(optimizer.population_size):
x = optimizer.ask()
value = quadratic(x[0], x[1])
solutions.append((x, value))
print(f"#{generation} {value} (x1={x[0]}, x2 = {x[1]})")
optimizer.tell(solutions)
And you can use this library via Optuna [Akiba et al. 2019], an automatic hyperparameter optimization framework. Optuna's built-in CMA-ES sampler which uses this library under the hood is available from v1.3.0 and stabled at v2.0.0. See the documentation or v2.0 release blog for more details.
import optuna
def objective(trial: optuna.Trial):
x1 = trial.suggest_uniform("x1", -4, 4)
x2 = trial.suggest_uniform("x2", -4, 4)
return (x1 - 3) ** 2 + (10 * (x2 + 2)) ** 2
if __name__ == "__main__":
sampler = optuna.samplers.CmaEsSampler()
study = optuna.create_study(sampler=sampler)
study.optimize(objective, n_trials=250)
CMA-ES variants
CatCMA with Margin [Hamano et al. 2025]
CatCMA with Margin (CatCMAwM) is a method for mixed-variable optimization problems, simultaneously optimizing continuous, integer, and categorical variables. CatCMAwM extends CatCMA by introducing a novel integer handling mechanism, and supports arbitrary combinations of continuous, integer, and categorical variables in a unified framework.
import numpy as np
from cmaes import CatCMAwM
def SphereIntCOM(x, z, c):
return sum(x * x) + sum(z * z) + len(c) - sum(c[:, 0])
def SphereInt(x, z):
return sum(x * x) + sum(z * z)
def SphereCOM(x, c):
return sum(x * x) + len(c) - sum(c[:, 0])
def f_cont_int_cat():
# [lower_bound, upper_bound] for each continuous variable
X = [[-5, 5], [-5, 5]]
# possible values for each integer variable
Z = [[-1, 0, 1], [-2, -1, 0, 1, 2]]
# number of categories for each categorical variable
C = [3, 3]
optimizer = CatCMAwM(x_space=X, z_space=Z, c_space=C)
for generation in range(50):
solutions = []
for _ in range(optimizer.population_size):
sol = optimizer.ask()
value = SphereIntCOM(sol.x, sol.z, sol.c)
solutions.append((sol, value))
print(f"#{generation} {sol} evaluation: {value}")
optimizer.tell(solutions)
def f_cont_int():
# [lower_bound, upper_bound] for each continuous variable
X = [[-np.inf, np.inf], [-np.inf, np.inf]]
# possible values for each integer variable
Z = [[-2, -1, 0, 1, 2], [-2, -1, 0, 1, 2]]
# initial distribution parameters (Optional)
# If you know a promising solution for X and Z, set init_mean to that value.
init_mean = np.ones(len(X) + len(Z))
init_cov = np.diag(np.ones(len(X) + len(Z)))
init_sigma = 1.0
optimizer = CatCMAwM(
x_space=X, z_space=Z, mean=init_mean, cov=init_cov, sigma=init_sigma
)
for generation in range(50):
solutions = []
for _ in range(optimizer.population_size):
sol = optimizer.ask()
value = SphereInt(sol.x, sol.z)
solutions.append((sol, value))
print(f"#{generation} {sol} evaluation: {value}")
optimizer.tell(solutions)
def f_cont_cat():
# [lower_bound, upper_bound] for each continuous variable
X = [[-5, 5], [-5, 5]]
# number of categories for each categorical variable
C = [3, 5]
# initial distribution parameters (Optional)
init_cat_param = np.array(
[
[0.5, 0.3, 0.2, 0.0, 0.0], # zero-padded at the end
[0.2, 0.2, 0.2, 0.2, 0.2], # each row must sum to 1
]
)
optimizer = CatCMAwM(x_space=X, c_space=C, cat_param=init_cat_param)
for generation in range(50):
solutions = []
for _ in range(optimizer.population_size):
sol = optimizer.ask()
value = SphereCOM(sol.x, sol.c)
solutions.append((sol, value))
print(f"#{generation} {sol} evaluation: {value}")
optimizer.tell(solutions)
if __name__ == "__main__":
f_cont_int_cat()
# f_cont_int()
# f_cont_cat()
The full source code is available here.
</details>We recommend using CatCMAwM for continuous+integer and continuous+categorical settings. In particular, [Hamano et al. 2025] shows that CatCMAwM outperforms CMA-ES with Margin in mixed-integer scenarios. Therefore, we suggest CatCMAwM in place of CMA-ES with Margin or CatCMA.
CatCMA [Hamano et al. 2024a]
CatCMA is a method for mixed-category optimization problems, which is the problem of simultaneously optimizing continuous and categorical variables. CatCMA employs the joint probability distribution of multivariate Gaussian and categorical distributions as the search distribution.
import numpy as np
from cmaes import CatCMA
def sphere_com(x, c):
dim_co = len(x)
dim_ca = len(c)
if dim_co < 2:
raise ValueError("dimension must be greater one")
sphere = sum(x * x)
com = dim_ca - sum(c[:, 0])
return sphere + com
def rosenbrock_clo(x, c):
dim_co = len(x)
dim_ca = len(c)
if dim_co < 2:
raise ValueError("dimension must be greater one")
rosenbrock = sum(100 * (x[:-1] ** 2 - x[1:]) ** 2 + (x[:-1] - 1) ** 2)
clo = dim_ca - (c[:, 0].argmin() + c[:, 0].prod() * dim_ca)
return rosenbrock + clo
def mc_proximity(x, c, cat_num):
dim_co = len(x)
dim_ca = len(c)
if dim_co < 2:
raise ValueError("dimension must be greater one")
if dim_co != dim_ca:
raise ValueError(
"number of dimensions of continuous and categorical variables "
"must be equal in mc_proximity"
)
c_index = np.argmax(c, axis=1) / cat_num
return sum((x - c_index) ** 2) + sum(c_index)
if __name__ == "__main__":
cont_dim = 5
cat_dim = 5
cat_num = np.array([3, 4, 5, 5, 5])
# cat_num = 3 * np.ones(cat_dim, dtype=np.int64)
optimizer = CatCMA(mean=3.0 * np.ones(cont_dim), sigma=1.0, cat_num=cat_num)
for generation in range(200):
solutions = []
for _ in range(optimizer.population_size):
x, c = optimizer.ask()
value = mc_proximity(x, c, cat_num)
if generation % 10 == 0:
print(f"#{generation} {value}")
solutions.append(((x, c), value))
optimizer.tell(solutions)
if optimizer.should_stop():
break
The full source code is available here.
</details>Safe CMA [Uchida et al. 2024a]
Safe CMA-ES is a variant of CMA-ES for safe optimization. Safe optimization is formulated as a special type of constrained optimization problem aiming to solve the optimization problem with fewer evaluations of the solutions whose safety function values exceed the safety thresholds. The safe CMA-ES requires safe seeds that do not violate the safety constraints. Note that the safe CMA-ES is designed for noiseless safe optimization. This module needs torch and gpytorch.
import numpy as np
from cmaes.safe_cma import SafeCMA
# objective function
def quadratic(x):
coef = 1000 ** (np.arange(dim) / float(dim - 1))
return np.sum((x * coef) ** 2)
# safety function
def safe_function(x):
return x[0]
"""
example with a single safety function
"""
if __name__ == "__main__":
# number of dimensions
dim = 5
# safe seeds
safe_seeds_num = 10
safe_seeds = (np.random.rand(safe_seeds_num, dim) * 2 - 1) * 5
safe_seeds[:,0] = - np.abs(safe_seeds[:,0])
# evaluation of safe seeds (with a single safety function)
seeds_evals = np.array([ quadratic(x) for x in safe_seeds ])
seeds_safe_evals = np.stack([ [safe_function(x)] for x in safe_seeds ])
safety_threshold = np.array([0])
# optimizer (safe CMA-ES)
optimizer = SafeCMA(
sigma=1.,
safety_threshold=safety_threshold,
safe_seeds=safe_seeds,
seeds_evals=seeds_evals,
seeds_safe_evals=seeds_safe_evals,
)
unsafe_eval_counts = 0
best_eval = np.inf
for generation in range(400